
Introduction
Single-Layer Perceptron的模擬實作,具體使用了基本的感知機學習演算法和收斂定理。輸入含有數個群組的多維資料集,將資料平均切分(每份大致同群數量相等),其中2/3資料給予程式訓練感知機,其餘1/3資料用於測試訓練完畢的感知機,目的為訓練出切割數個群組的超平面與鍵結值,顯示結果於圖形介面。
Repo:https://github.com/Jasonnor/Perceptron

本程式以Java開發,圖形介面使用Java Swing & GUI Bulider,同時也是第一次使用IntelliJ IDEA這個JetBrains開發的IDE,相較免費的Eclips,實用的快捷鍵和人性化的介面是其一大優勢。
Program Interface
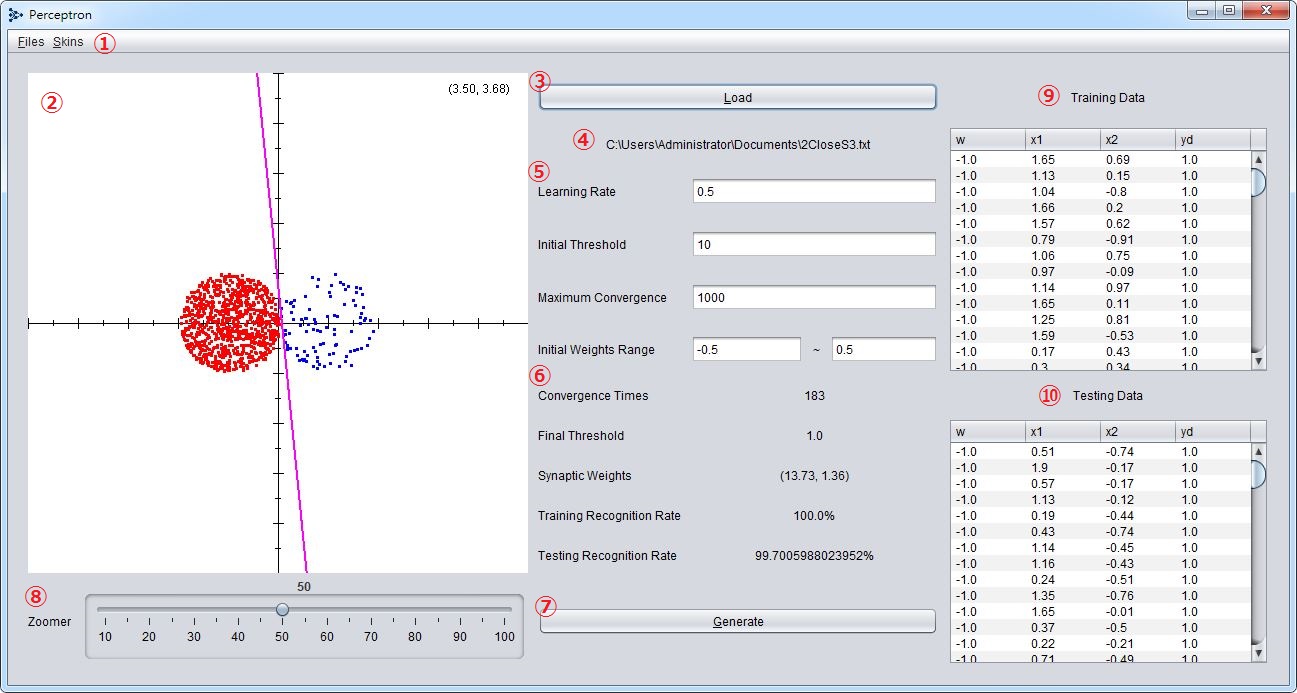
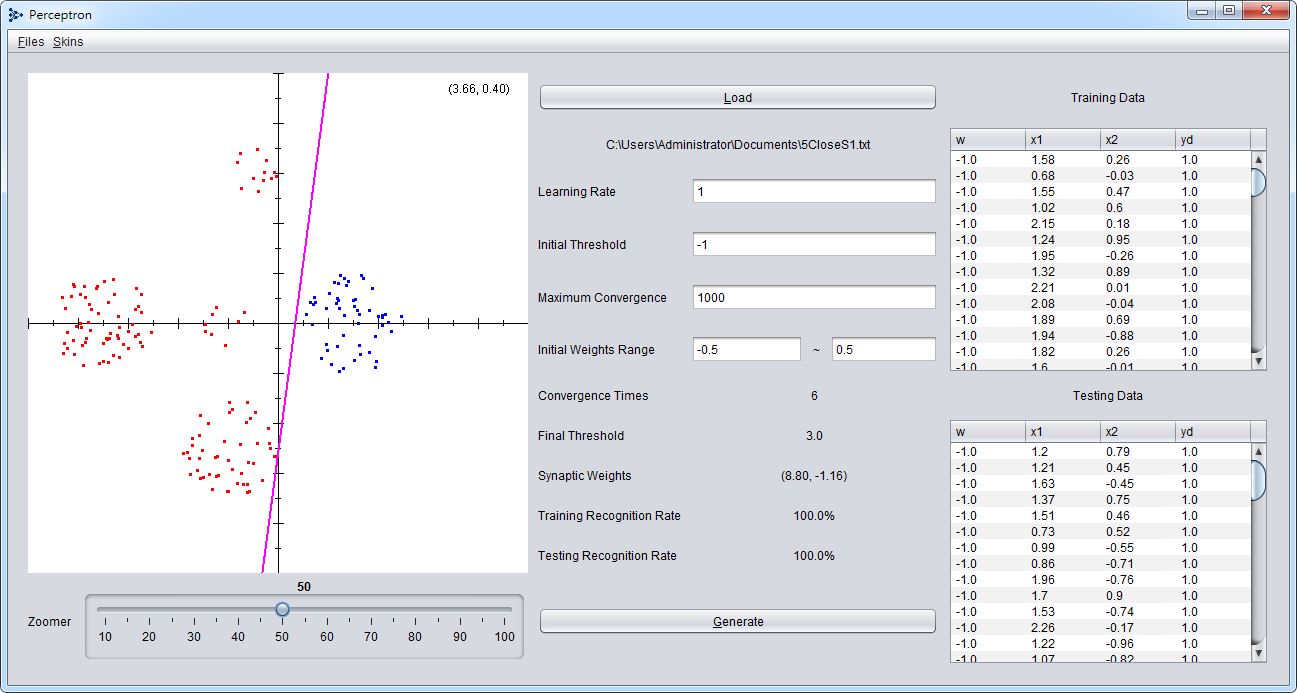
- 操作選單(Files、Skins)
- 輸出結果畫面(右上角的數字為滑鼠當前座標)
- 讀取檔案
- 檔案所在路徑
- 可調整參數(學習率、初始閥值、最大收斂次數、初始隨機鍵結值範圍)
- 輸出結果(收斂次數、最終閥值、最終鍵結值、訓練辨識率、測試辨識率)
- 產生新的結果
- 調整輸出結果畫面縮放等級
- 訓練用資料一覽(占總資料2/3)
- 測試用資料一覽(占總資料1/3)
可以使用預設的資料集來進行測試。
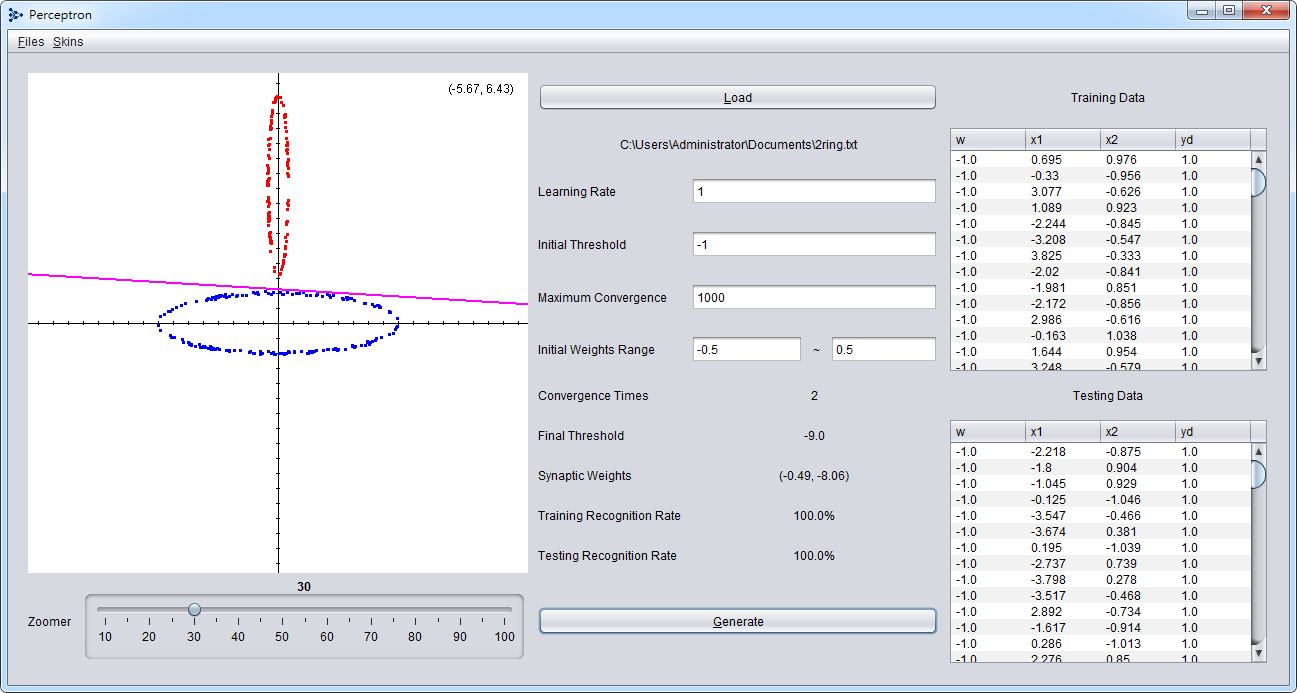
Demo
Program Structure
當初寫的時間非常趕,基本上是完全塞一個Class的凌亂架構,之後有時間會再進行重構。

基本公共變數,包含表格模型、顏色陣列、輸入資料陣列(原始、訓練、測試)、鍵結值陣列(應對多群狀況)、群組陣列(包含哪些可能輸出群組)和滑鼠位置,下方區塊為使用者可調整參數。

Class Constructor,大多用於建構GUI事件監聽函數和後續動作處理。
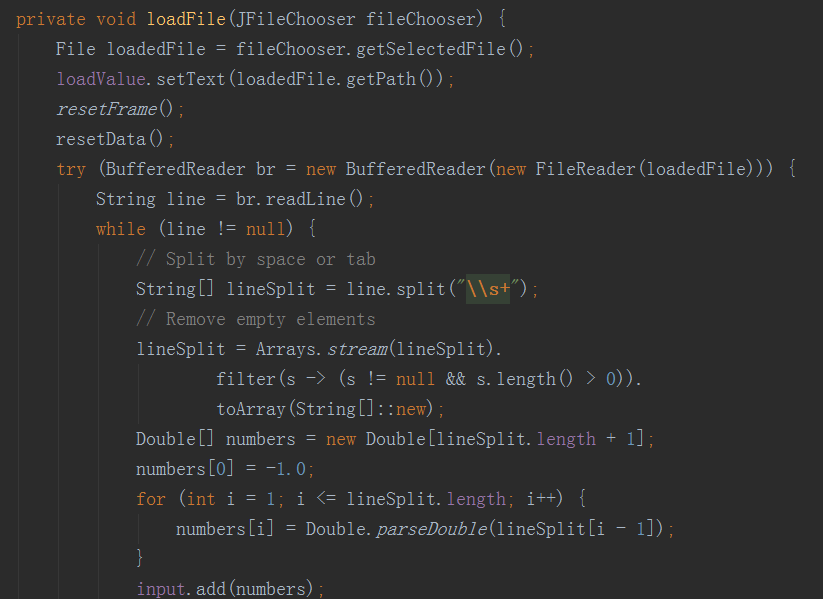
讀取檔案函式,將資料處理後存入公共變數,同時做切割訓練與測試資料部分。
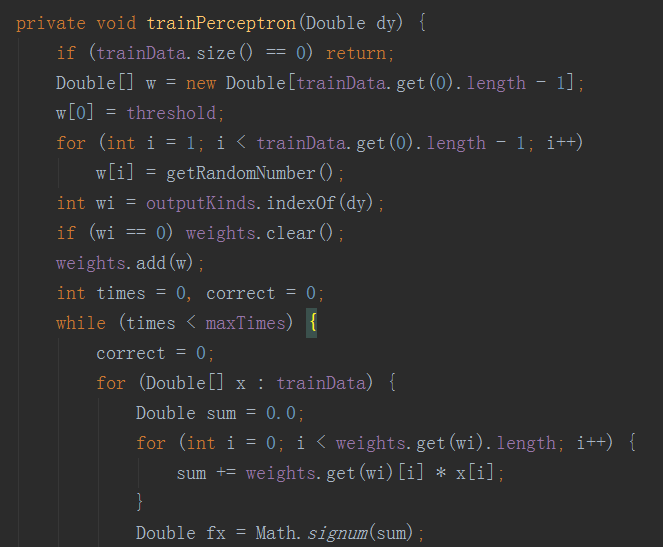
訓練感知機函式,輸入為要區分的群的期望Y值(若大於2群,N群則使用N個感知機),求出鍵結值等輸出。

測試感知機函式,基本同訓練函式,主要驗證訓練結果是否良好。
其餘大多是功能類函式,在此省略。
Result Analysis
基本上線性可分割的資料群都一定能收斂達到完全分類成功,但某些點較為貼近的資料集,如果收斂次數(訓練次數)不夠高還是有可能出現沒有100%辨識的狀況。本程式整合了許多可調整的參數,包含學習率、初始閥值、最大收斂次數和初始隨機鍵結值範圍,提供最大化測試每種參數對感知機的影響。
學習率在大資料集的影響較大,如果值越小越能找到精細的高準確結果,但是收斂次數會相對大幅增加,反之則能在較少的次數中得到結果;閥值則是根據不同樣本會有極大差異,初始閥值如果抓得相當準確,則可能少練訓練就能得出結果,反之則也有機會讓限定次數的訓練得不出準確成果,初始的隨機鍵結值亦然,不過大多推薦設定在接近零的極小值以方便快速調整正負誤差,也因此有許多演算法試圖找出較好的初始閥值或鍵結值來大幅提升訓練效能。
由於資料集切割為訓練和測試兩種樣本群,導致部分資料數低的檔案在測試結果會有較差的表現,可以看出類神經網路大多系統建立在樣本數夠高的前提,否則在精準的訓練都是白搭。
Difficulties Encountered
處理多群的資料遭遇到了一些困難,主要是一開始取期望輸出都是(+1, -1),改為多群需要將原本的程式全部重寫。處理多群有幾種作法:使用N個感知機、使用logN(底數2)個感知機、使用1個感知機(切分輸出),我選擇了最容易實作的第一種。基本上只要將每群分別做訓練就能得出結果,目標群當作+1,其他以外作為-1,如此就能切出N種(屬於該群,不屬於該群)的分割平面。
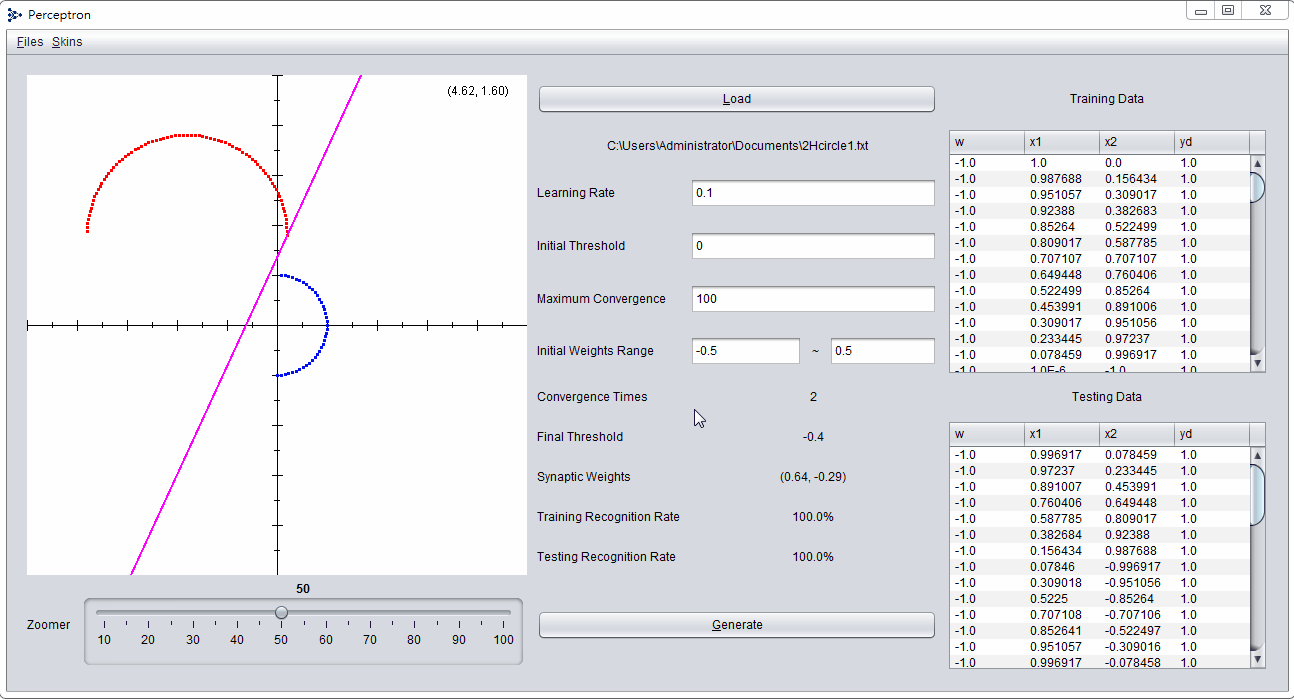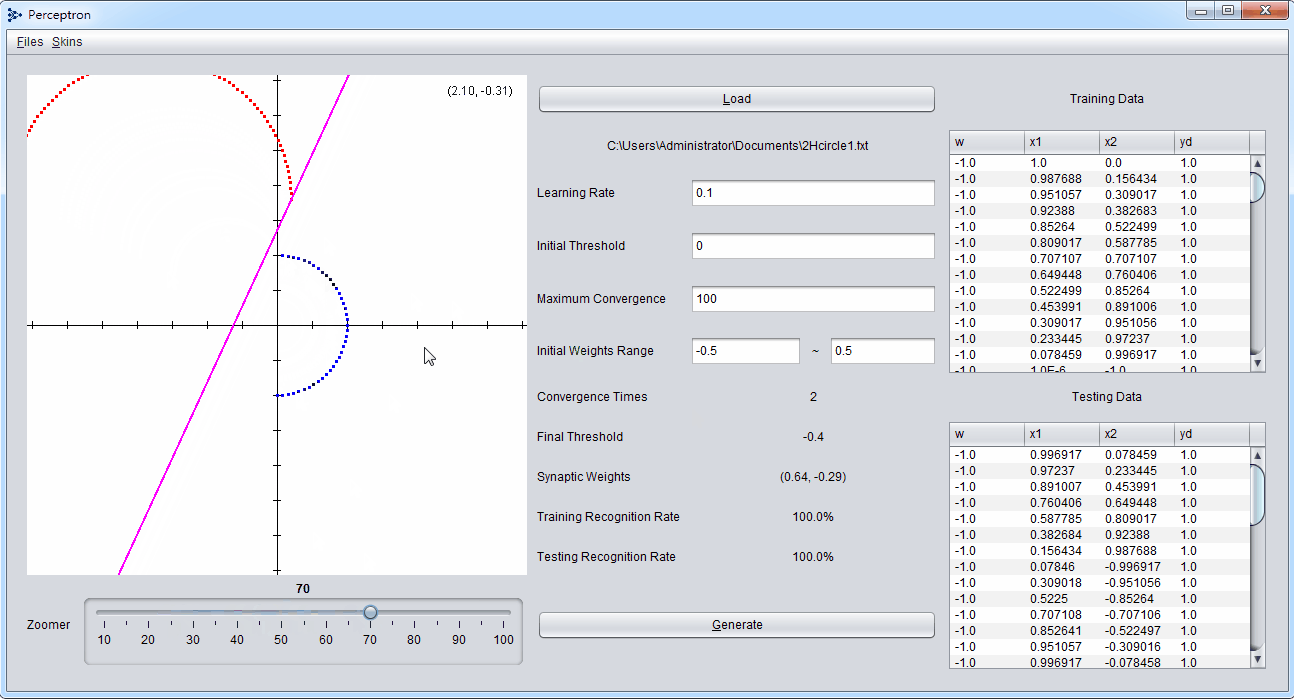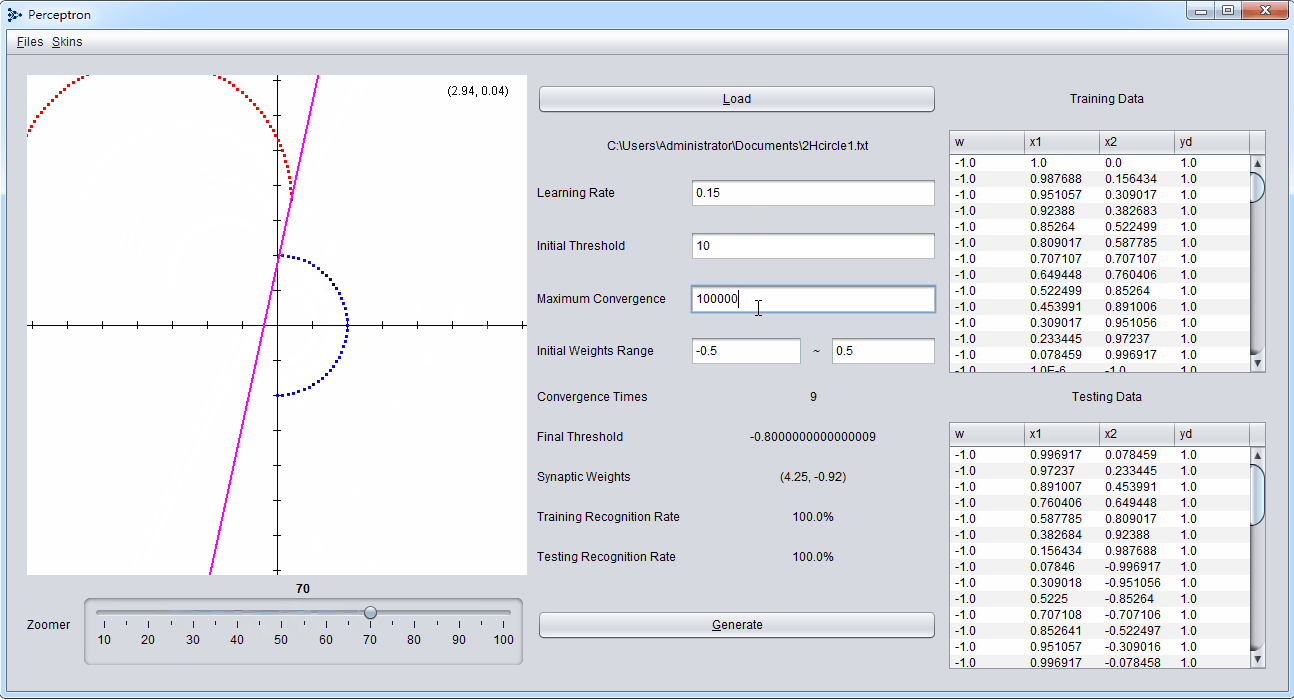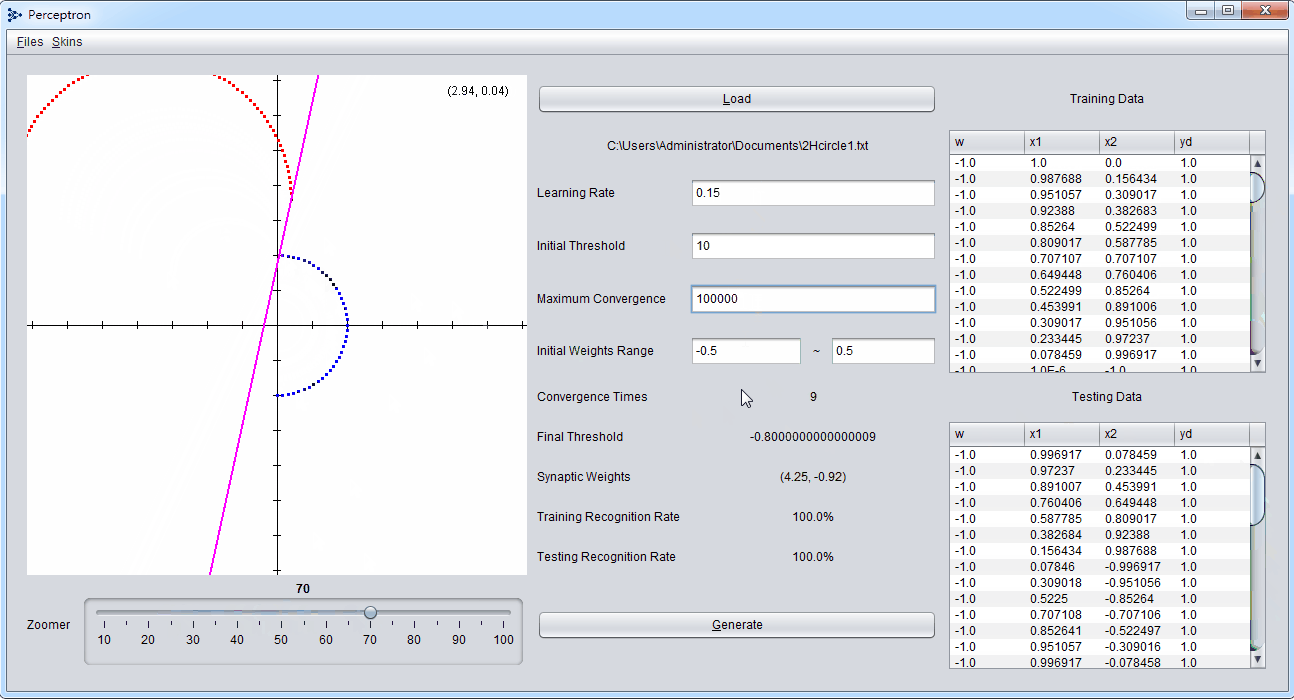
包含雜訊的不可分割資料集也令人相當苦惱,2Circle2.txt中就包含了數點的異群雜訊,導致感知機得出結果不佳,不考慮多層感知機的前提,後續可以考慮增加過濾雜訊處理的選項。
最後就是處理GUI花了相當多時間,尤其是座標系的轉換有時候會搞混導致繪製失誤。
Conclusion
這是幾個月前學習類神經網路的一個實作程式,開發過程幫我釐清許多感知機演算法的觀念,也在加深了對類神經網路的理解,收益良多。
最後,本篇文章寫於剛接觸類神經網路的時段,還沒有仔細勘正,如果有發現錯誤或觀念不正確的地方歡迎提出指教,非常感謝!