

Figure 1: 輸入「笑傲江湖」文件集合,每份文件為小說中的一個章回,輸出每章前 K 高的字詞和其權重。
簡介
tf-idf(term frequency-inverse document frequency)是一種用於資訊檢索與文字探勘的常用加權技術,為一種統計方法,評估字詞對於「文件集合」或「語料庫中的一份文件」的重要程度。詳細方法和公式可參見Wikipedia,不再贅述。
本項目為實作 tf-idf ,輸入給定「一組有特定集合關系的文件」(例如某本小說),輸出為每份文件的 tf-idf 權重值結果,具體為顯示前 k 高的「字詞」和其權重值,如 Figure 1 所示。另外也可以輸入某個字詞,輸出該字詞在所有文件中的權重值。
Repo:https://github.com/Jasonnor/tf-idf-python
因為中文無法像英文可以藉由空白來區隔字詞,我們采用了 jieba 結巴中文分詞,將文件集合先進行分詞獲得語料庫,之後使用 tf-idf 演算法取得字詞加權值。
預設測試資料位於 data 資料夾底下,每組文件以 01 ~ 99.txt 格式命名,並放置到各別所屬集合的資料夾,例如 data/笑傲江湖/01.txt 。測試資料包含笑傲江湖、創世紀、出埃及記。
jieba 其實也內建了「基於 TF-IDF 算法的關鍵詞抽取」,不過根據它的文件和 Source Code 所述, jieba 其實只讀取一個文件來計算TF,而IDF部分則是讀取他們自定的語料庫,因此結果不准確(不是基於相關文件集合來計算逆頻率)。具體可以試試目錄下的src/tf-idf-jieba.py,我寫了簡單的 jieba 版本 Demo。
預覽
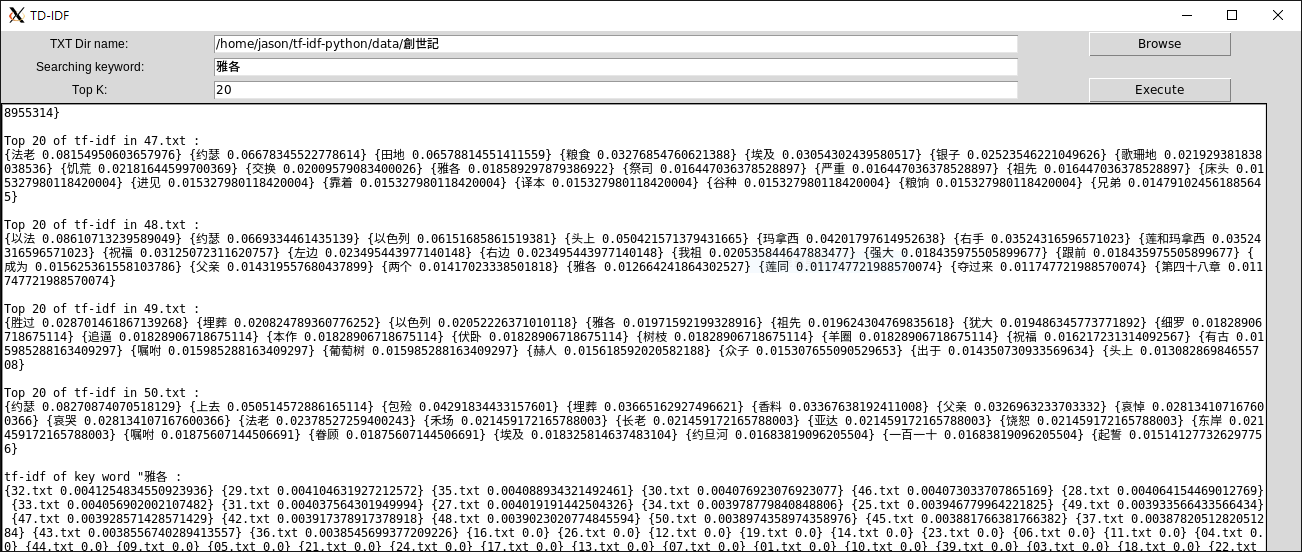
簡易GUI

「笑傲江湖」資料集的各章字詞權重列表,可以看到各章節的重要關鍵字排名

字詞「任我行」在各章節的權重排名,可以看到他在第28章出場最多,而數值為0的部分就能得知他沒有出現
結論
tf-idf 這個統計方法可以應用在許多場合,處理小說只是其中一種。不過 tf-idf 儘管簡單有效,卻存在部分重大缺陷。以我個人發現的例子來說,笑傲江湖資料集裡每章基本上都一定會出現主角的名字「令狐沖」這個字詞,然而對 tf-idf 來說,每章都出現的東西代表它是常用字詞,逆頻率的存在使「令狐沖」的權重反而變為 0,這真是很諷刺的結果。
可以見得 idf 的簡單架構不能有效反映常見字詞和重要字詞的比重,精確度並不是很高。另外位置資訊也是其缺陷一環,不過在小說中這種缺點並不明顯,因此不多做討論。